从hugging face下载数据集,将.parquet类型数据中提取图片和标签 |
您所在的位置:网站首页 › the one图片 › 从hugging face下载数据集,将.parquet类型数据中提取图片和标签 |
从hugging face下载数据集,将.parquet类型数据中提取图片和标签
|
时间:2024.1.19 1.hugging face数据集下载地址 https://huggingface.co/datasets?sort=downloads 2.下载.paraquet类型数据(1)这里以图像文本对数据集pokeman为例。先点击下图中左侧的text-to-image,再点击pokeman-blip-captions。 .parquet类型数据如下: 注意:代码中的路径要根据实际路径进行修改!! import pandas as pd import cv2 import numpy as np pokeman = pd.read_parquet('/root/train-00000-of-00001-566cc9b19d7203f8.parquet') print(pokeman) path_prefix = '/root/pokeman/' print('Processing images : ') for index, img in enumerate(pokeman['image']): image_bytes = img['bytes'] # 将bytes数据转换为numpy矩阵 image_np = cv2.imdecode(np.frombuffer(image_bytes, dtype=np.uint8), cv2.IMREAD_COLOR) # 将numpy矩阵保存为jpg格式的图片文件 cv2.imwrite(path_prefix + f"/image/{index}.jpg", image_np) print('finish') print('Processing text : ') for index, text in enumerate(pokeman['text']): with open(path_prefix + f'/text/{index}.txt', 'w') as f: f.write(text) print('finish') 5.任务这个pokeman是一个图像文本对数据集,听说能训练stable diffusion,后续试一试。 |
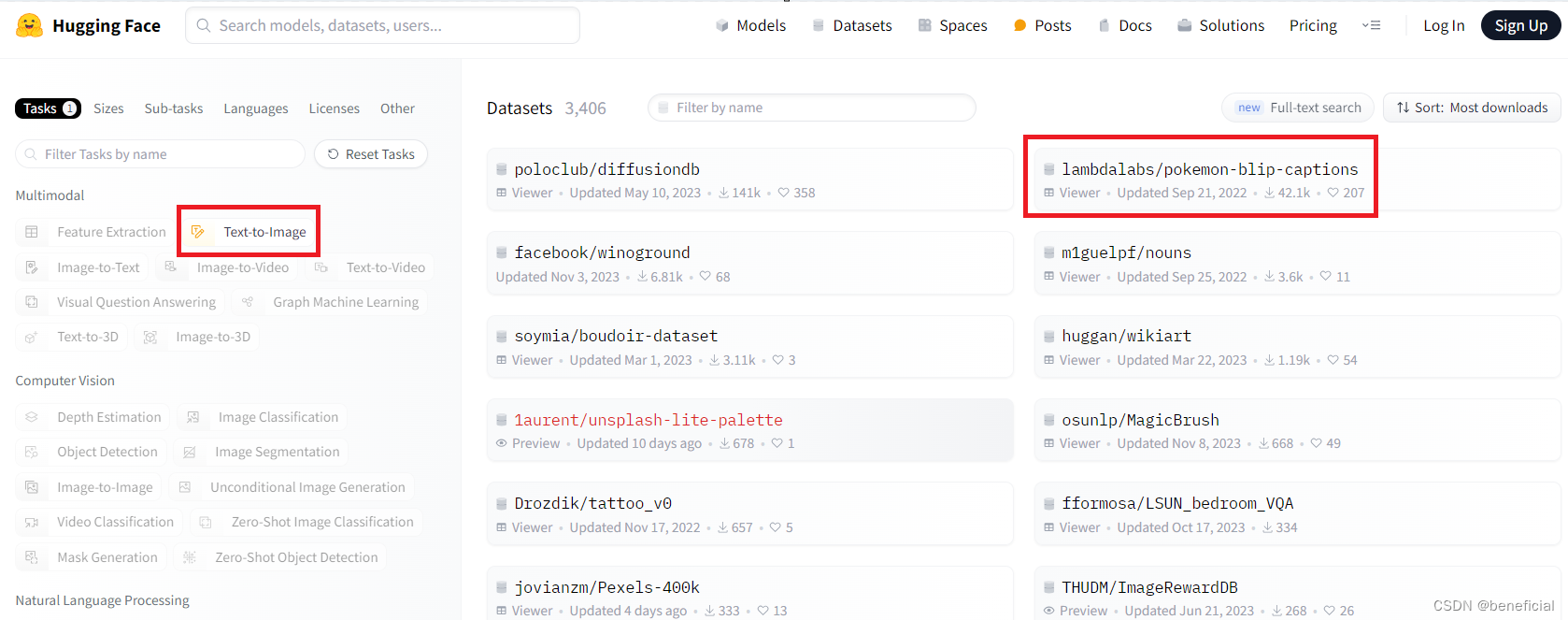 (2)再点击下图中的File and version,再点击下载按钮。
(2)再点击下图中的File and version,再点击下载按钮。 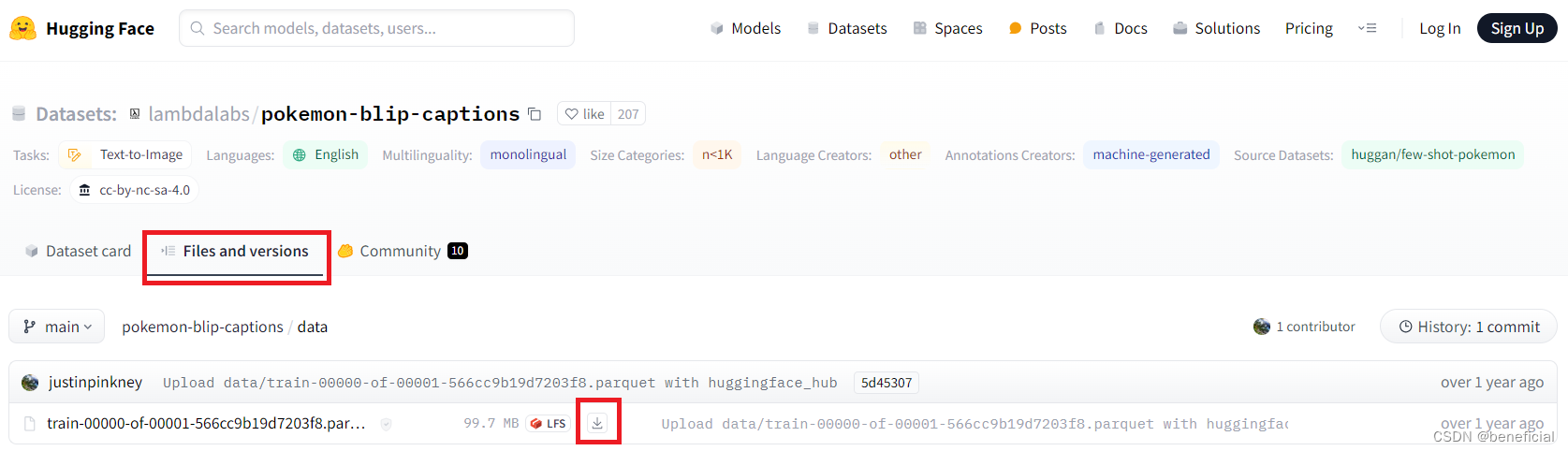
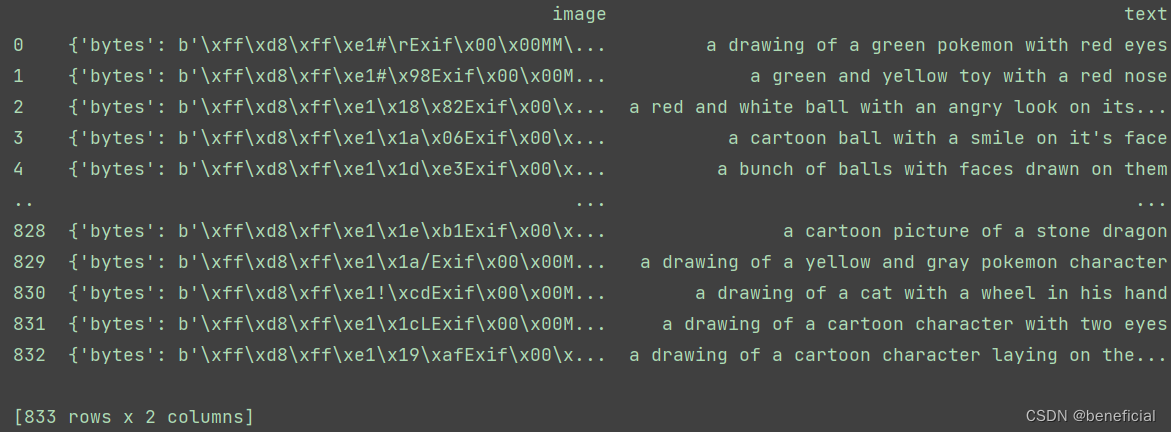 可以看到有833条数据,每一个数据都包含1张图片和1条文本。
可以看到有833条数据,每一个数据都包含1张图片和1条文本。【本文地址】
今日新闻 |
推荐新闻 |